How well can your Multimodal model jointly reason over text and image in text-rich scenes?


Models are becoming quite good at understanding text on its own, but what about text in images, which gives important contextual information? For example, navigating a map, or understanding a meme? The ability to reason about the interactions between the text and visual context in images can power many real-world applications, such as AI assistants, or tools to assist the visually impaired.
We refer to these tasks as “context-sensitive text-rich visual reasoning tasks”.
At the moment, most evaluations of instruction-tuned large multimodal models (LMMs) focus on testing how well models can respond to human instructions posed as questions or imperative sentences (“Count this”, “List that”, etc) over images… but not how well they understand context-sensitive text-rich scenes!
That’s why we (researchers from University of California Los Angeles) created ConTextual, a Context-sensitive Text-rich visuaL reasoning dataset for evaluating LMMs. We also released a leaderboard, so that the community can see for themselves which models are the best at this task.
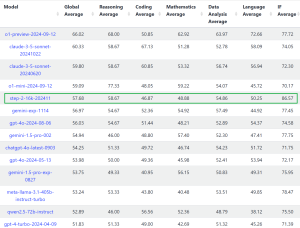
For an in-depth dive, you can also check these additional resources: paper, code, dataset, validation dataset, and leaderboard.
What is ConTextual
ConTextual is a Context-sensitive Text-rich visual reasoning dataset consisting of 506 challenging instructions for LMM evaluation. We create a diverse set of instructions on text-rich images with the constraint that they should require context-sensitive joint reasoning over the textual and visual cues in the image.
It covers 8 real-world visual scenarios – Time Reading, Shopping, Navigation, Abstract Scenes, Mobile Application, Webpages, Infographics and Miscellaneous Natural Scenes. (See the figure for a sample of each dataset).

Each sample consists of:
- A text-rich image
- A human-written instruction (question or imperative task)
- A human-written reference response
The dataset is released in two forms:
- (a) a validation set of 100 instances from the complete dataset with instructions, images, and reference answers to the instructions.
- (b) a test dataset with instructions and images only.
The leaderboard contains model results both on the validation and test datasets (the information is also present in the paper). The development set allows the practitioners to test and iterate on their approaches easily. The evaluation sandbox is present in our github.
Experiments
For our initial experiments, our benchmark assessed the performance of 13 models. We divided them into three categories:
- Augmented LLM approach: GPT4 + visual information in the form of OCR of the image and/or dense image captions;
- Closed-Source LMMs: GPT4V(ision) and Gemini-Vision-Pro;
- Open-Source LMMs: LLaVA-v1.5-13B, ShareGPT4V-7B, Instruct-Blip-Vicuna-7B, mPlugOwl-v2-7B, Bliva-Vicuna-7B, Qwen-VL-7B and Idefics-9B.
Our dataset includes a reference response for each instruction, allowing us to test various automatic evaluation methods. For evaluation, we use an LLM-as-a-judge approach, and prompt GPT-4 with the instruction, reference response, and predicted response. The model has to return whether the predicted response is acceptable or not. (GPT4 was chosen as it correlated the most with human judgement in our experiments.)
Let’s look at some examples!
Example 1
In this instance, GPT-4V provides an incorrect response to the instruction, despite its logical reasoning. The use of green indicates responses that match the reference, while red highlights errors in the responses. Additionally, a Summarized Reasoning is provided to outline the rationale used by GPT-4V to arrive at its answer.
Example 2
In this example, GPT-4V correctly responds to the instruction. However, ShareGPT-4V-7B (best performing open-source LMM) and GPT-4 w/ Layout-aware OCR + Caption (Augmented LLM) produce a wrong response, due to lack of joint reasoning over text and image.
You’ll find more examples like this in the Appendix section of our paper!
Key Takeaways!
While working on this, we found that:
- Modern LMMs (proprietary and open models) struggle to perform on ConTextual dataset while humans are good at it, hinting at the possibility of model improvement to enhance reasoning over text-rich images, a domain with significant real-world applications.
- Proprietary LMMs perform poorly in infographics reasoning that involves time reading, indicating a gap in their capabilities compared to humans. Notably, GPT-4V, the best performing model, surpasses humans in abstract reasoning, potentially due to exposure to memes and quotes data, but struggles in time-related tasks where humans excel.
- For open-source models such as LLaVA-1.5-13B and ShareGPT-4V-7B, there is a strong gap between the domains on which they achieve acceptable human ratings (abstract and natural scene contexts) and the other domains ((time-reading, infographics, navigation, shopping, web, and mobile usage). It’s therefore likely that many of the domains we cover in our samples are out-of-distribution for these models. Open-source models should therefore aim to increase the diversity in their training data.
- Augmenting an LMMs with a Large Language Model, which receives visual information converted into text via OCR or captions, performs notably badly, with an human approval rate of 17.2%. Our samples need a combination of precise visual perception along with fine-grained nuanced vision-language alignment to be solved.
Our analysis suggests promising next steps include:
- developing enhanced image encoders,
- creating highly accurate image descriptions,
- facilitating fine-grained vision-language alignment to improve the model’s perception and mitigate the occurrence of hallucinations.
This, in turn, will lead to more effective context-sensitive text-rich visual reasoning.
What’s next?
We’d love to evaluate your models too, to help collectively advance the state of vision language models! To submit, please follow our guidelines below.
We hope that this benchmark will help in developing nuanced vision-language alignment techniques and welcome any kind of collaboration! You can contact us here: Rohan and Hritik, and know more about the team here: Rohan, Hritik, Kai-Wei Chang, Nanyun (Violet) Peng.
How to Submit?
We are accepting submissions for both the test and validation sets. Please, follow the corresponding procedure below.
Validation Set Submission
To submit your validation results to the leaderboard, you can run our auto-evaluation code (Evaluation Pipeline with GPT4), following these instructions.
We expect submissions to be json format as shown below:
{"model_name": {"img_url": "The boolean score of your model on the image, 1 for success and 0 for failure"}}
- Replace model name with your model name (string)
- Replace img_url with img_url of the instance (string)
- Value for an img url is either 0 or 1 (int)
There should be 100 predictions, corresponding to the 100 urls of the val set.
To make the submission please go to the leaderboard hosted on HuggingFace and fill up the Submission form.
Test Set Submission
Once you are happy with your validation results, you can send your model predictions to Rohan and Hritik.
Please include in your email:
- A name for your model.
- Organization (affiliation).
- (Optionally) GitHub repo or paper link.
We expect submissions to be json format similar to val set as shown below:
{"model_name": {"img_url": "predicted response"}}
- Replace model name with your model name (string)
- Replace img_url with img_url of the instance (string)
- Value for an img url is the predicted response for that instance (string)
There should be 506 predictions, corresponding to the 506 urls of the test set.





{kind=link}
{kind=link}